


拋光打磨機(jī)器人模仿方式以及方法概覽
2022-09-13 22:19:32 0次
1)運(yùn)動(dòng)模型:以DMP、GMM和GMR等傳統(tǒng)的示教學(xué)習(xí)方法為代表。解決的運(yùn)動(dòng)規(guī)劃問(wèn)題,需要明確知道機(jī)器人和目標(biāo)點(diǎn)的的位置姿態(tài)信息,同時(shí)也需要有結(jié)構(gòu)化的環(huán)境信息(障礙等)。該類方法的基礎(chǔ)是概率模型,需要建立示教軌跡的參數(shù)依賴模型,然后針對(duì)新任務(wù)進(jìn)行解碼。
2)策略學(xué)習(xí)模型:以學(xué)徒學(xué)習(xí)、最大邊際規(guī)劃、逆強(qiáng)化學(xué)習(xí)和生成對(duì)抗模仿學(xué)習(xí)為代表。該類方法需要將單純的運(yùn)動(dòng)規(guī)劃問(wèn)題、規(guī)劃+控制問(wèn)題或感知+規(guī)劃+控制問(wèn)題建模為多步?jīng)Q策問(wèn)題,然后利用DNN來(lái)學(xué)習(xí)策略。理論基礎(chǔ)是強(qiáng)化學(xué)習(xí)那一套,但引入了專家示教等。
3)語(yǔ)義推理模型:對(duì)于任務(wù)進(jìn)行高語(yǔ)義層級(jí)的解析和歸納,然后基于語(yǔ)義進(jìn)行推理。如果是做研究,第一類方法沒(méi)有太多可以探索的點(diǎn)。遷移學(xué)習(xí)的難點(diǎn)還是在于對(duì)任務(wù)configuration理解與對(duì)環(huán)境的感知。第二類方法需要大量數(shù)據(jù),示教數(shù)據(jù)中需要遷移的信息密度很低。第三類方法信息密度高,但在符號(hào)主義方法產(chǎn)生重大突破之前,這類方法其實(shí)也沒(méi)有太多可以做的。
模仿學(xué)習(xí)面臨的一個(gè)挑戰(zhàn)是:平衡模仿演示行為的能力,以及演示狀態(tài)分布之外的狀態(tài)恢復(fù)能力。BC 通過(guò)監(jiān)督學(xué)習(xí)來(lái)模仿演示的動(dòng)作,而 IRL 專門(mén)研究如何從任意狀態(tài)中恢復(fù)策略。ROT 可以將兩者優(yōu)勢(shì)結(jié)合起來(lái)。
完成上述過(guò)程分為以下兩個(gè)階段:
第一階段,在專家演示數(shù)據(jù)上使用 BC 目標(biāo)訓(xùn)練隨機(jī)初始化策略,然后 BC 預(yù)訓(xùn)練策略用作第二階段的初始化;
第二階段,BC 預(yù)訓(xùn)練策略可以訪問(wèn)使用 IRL 目標(biāo)進(jìn)行訓(xùn)練的環(huán)境。為了加速 IRL 訓(xùn)練,BC 損失被添加到具有自適應(yīng)權(quán)重目標(biāo)中。
階段 1:BC 預(yù)訓(xùn)練
BC 對(duì)應(yīng)于求解方程 2 中的最大似然問(wèn)題,其中 T^e 指的是專家演示。當(dāng)由具有固定方差的正態(tài)分布參數(shù)化方程時(shí),我們可以將目標(biāo)定義為回歸問(wèn)題,其中給定輸入 s^e,π^BC 需要輸出 a^e。
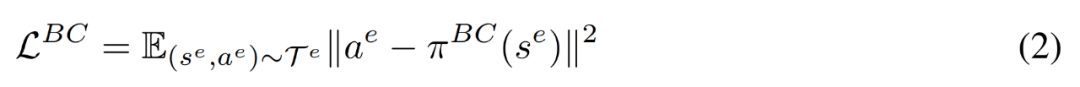
經(jīng)過(guò)訓(xùn)練,π^BC 能夠模擬與演示中看到的對(duì)應(yīng)動(dòng)作。
階段 2:使用 IRL 進(jìn)行在線微調(diào)
給定一個(gè)預(yù)訓(xùn)練 π^BC 模型,在環(huán)境中對(duì)策略 π^b ≡ π^ROT 進(jìn)行在線微調(diào)。研究者使用 n-step DDPG 方法,這是一種基于確定性 actor-critic 的方法,可在連續(xù)控制中提供高模型性能。
用正則化 π^BC 進(jìn)行微調(diào)很容易受到分布偏移的影響,并且直接微調(diào) π^BC 也會(huì)導(dǎo)致模型性能不佳(參見(jiàn)第 3 節(jié)中的圖 2)。為了解決這個(gè)問(wèn)題,研究者基于引導(dǎo) RL(guided RL) 和離線 RL 方法,通過(guò)將π^ROT 與 BC 損失相結(jié)合,將π^ROT 的訓(xùn)練規(guī)范化,如下方程 3 所示。

具有 Soft Q-filtering 的自適應(yīng)正則化。雖然之前的工作使用經(jīng)過(guò)手動(dòng)調(diào)優(yōu)的 λ(π) 時(shí)間表,但研究者提出了一種新的、無(wú)需調(diào)優(yōu)的自適應(yīng)方案。他們通過(guò)在從專家 replay 緩沖區(qū) D_e 采樣的一批數(shù)據(jù)中比較當(dāng)前策略 π^ROT 和預(yù)訓(xùn)練策略 π^BC 的性能來(lái)完成。





